工作上遇到一个多对多join的逻辑问题如下:
要把优惠券使用数据(优惠券金额,优惠券发放时间、优惠规则和优惠活动等信息),和使用优惠券的销售信息(买了什么商品,商品价格多少,商品品类等等)join到一起。因为种种原因,这两个数据没法对起来,一个系统没有记录另一个系统的逻辑或者流水PK。
当N:1 join的时候,1的那条数据会重复:
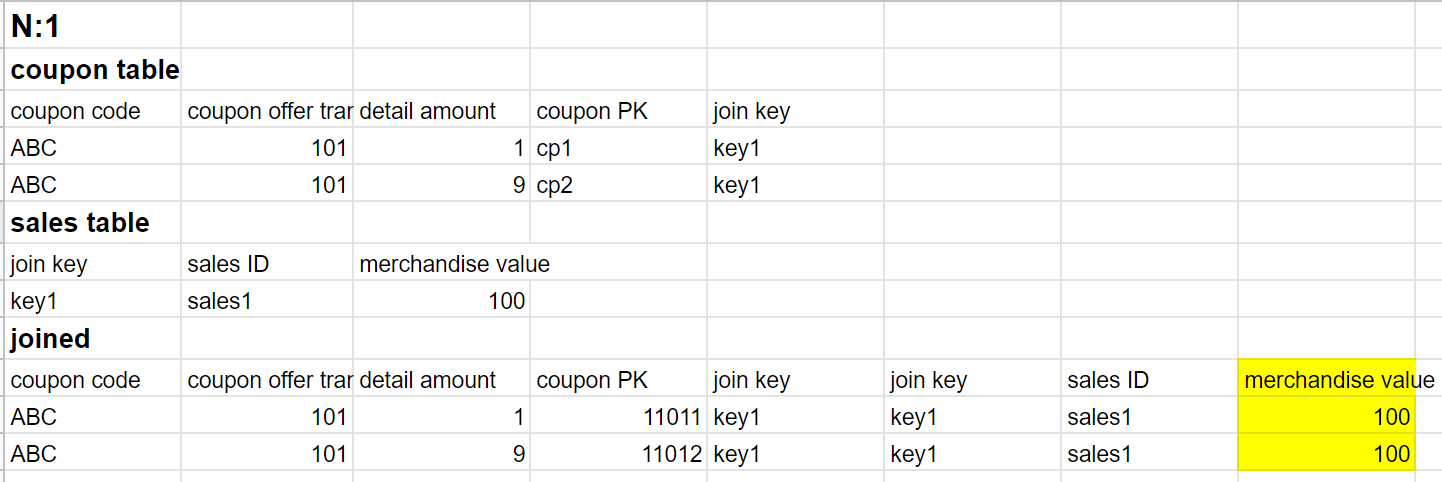
这时,最终结果表里的销售额如果直接相加,就会得到200,和实际情况不符。实际上,这个项目要做的表原先有一个版本,就是这样存数据的。我觉得这样很不好,因为这个表就不符合一般的数据库规范。我们用这个表的时候必须把100去重以后再用:
-- wrong
select sum([merchandise value])
from joined_table
;
-- correct
select sum([merchandise value])
from (
select
[coupon PK]
,[sales ID]
,max([merchandise value]) as [merchandise value]
from joined_table
group by 1,2
) a
;当1:M join的时候,同样的,1的记录会重复:
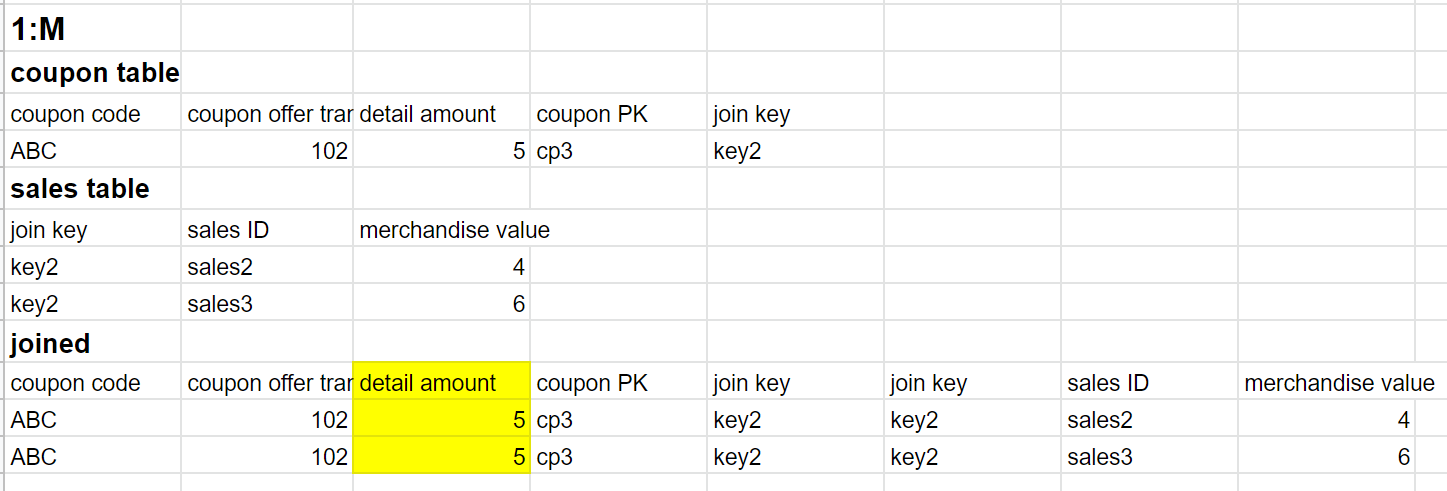
优惠券是5块钱,如果reporting的时候算成了10块钱就不对了。按理说这种情况也可以按照上面那种办法处理。然而现在的情况是,最终我们的是M:N的join。
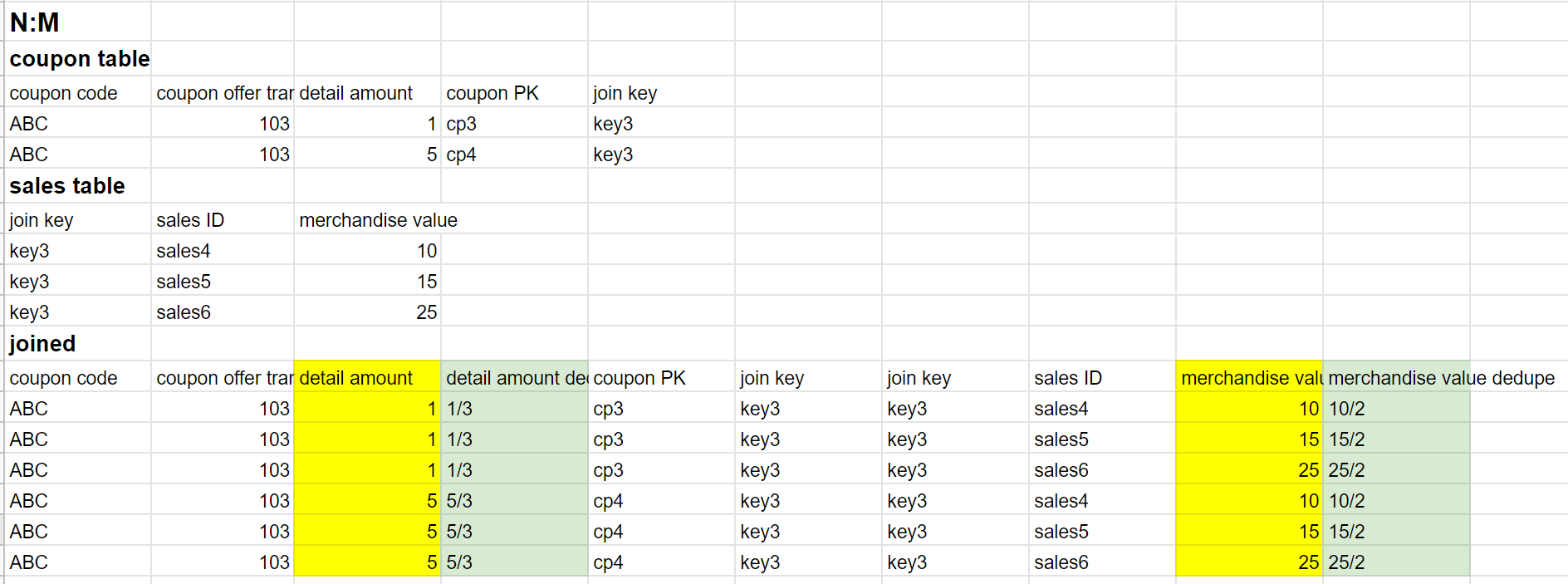
我想出的解决方法是,数一下那个值重复了几次,然后把值拆开来,比如如上图除一下平均分摊(最终我按照另一端的数值加权平均的)。
select
a.[coupon code]
,a.[coupon PK]
,a.[detail amount]/sum(1)over(partition by a.[coupon PK]) [detail amount deduped]
,b.[sales ID]
,b.[merchandise value]/sum(1)over(partition by b.[sales ID]) [merchandise value deduped]
from [coupon table] a
join [sales table] b
on a.[join keys]=b.[join keys]
;说一下感想:我从来没有遇到过必须多对多join的统计数据。有时候我们需要逻辑上的多对多join,比如把几个日期分配到一个表里的所有记录上。但是对于统计metrics的表,如果join在不理解的字段上,就要看一下是不是有join字段造成数据重复的问题。
这个项目战线大概有一年。和所有的事情一样,正在发生时难以像上面那样概括出问题症结。我一开始以为,两种数据可以有很清晰的关联。没想到,每次看见不太对的地方,追问了以后得到的建议是看另一种数据。而存数据的一方,现在总是把数据都存到一个json里面去。当你在数据库里存json的时候,其实经常就是打破数据库原有的关系。为了分析这些json我把存了好多年的表整个重建了好几次。因为解开了json里存的数据,上述的coupon数据表的PK就变得模糊,更让人看不清数据重复了。
这个项目另外一个奇葩的地方是,数据我最终是分成5块用5种字段组合join的。其中4种有多对多的情况。好几个join是我肉眼观测到可能可以join然后找人确认的。我多次跟同事宣称我觉得这样很不靠谱。而我的pm无法理解数据。我没法让他理解我的重复并不是‘多个coupon用在了多个商品上’这么简单(我肉眼观测到的join是不是就代表了两端的这个数据一定有关联也不是确定的)。而我的同事谁也不觉得这种数据有什么不对的。这件事让我十分崩溃。我同事还问我为什么不能像以前那样把重复的数值存在表里。(两个有重复的字段,并且在不同的group里重复,就是没办法写出上面那种SQL来使用这个数据的。)
我其实是很喜欢解决新问题的。但是这个问题的解决方案完全是为了完成而写的,最终并没有反映数据逻辑(主要是PM也不愿去理解业务的逻辑),让人难受。